
 United States
United States
 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
TACC2 (NM_001291877) Human Tagged ORF Clone
CAT#: RG240259
- TrueORF®
TACC2 (tGFP-tagged) - Human transforming, acidic coiled-coil containing protein 2 (TACC2), transcript variant 6
ORF Plasmid: DDK
"NM_001291877" in other vectors (2)
Need custom modification / cloning service?
Get a free quote
CNY 33,160.00
Product images

CNY 1,999.00
CNY 2,700.00
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | TurboGFP |
| Synonyms | AZU-1; ECTACC |
| Vector | pCMV6-AC-GFP |
| E. coli Selection | Ampicillin (100 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RG240259 representing NM_001291877.
Blue=ORF Red=Cloning site Green=Tag(s) GCTCGTTTAGTGAACCGTCAGAATTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTG GATCCGGTACCGAGGAGATCTGCCGCCGCGATCGCC ATGGGCAATGAGAACAGCACCTCGGACAACCAGAGGACTTTATCAGCTCAGACTCCAAGGTCCGCGCAG CCACCCGGGAACAGTCAGAATATAAAAAGGAAGCAGCAGGACACGCCCGGAAGCCCTGACCACAGAGAC GCGTCCAGCATTGGCAGCGTTGGGCTTGGAGGCTTCTGCACCGCTTCTGAGAGTTCTGCCAGCCTGGAT CCATGCCTTGTGTCCCCAGAGGTGACTGAGCCAAGGAAGGACCCACAGGGAGCCAGGGGGCCAGAAGGT TCTTTGCTGCCCAGCCCACCACCGTCCCAGGAGCGAGAGCACCCCTCGTCCTCCATGCCCTTTGCCGAG TGTCCCCCGGAAGGTTGCTTGGCAAGTCCAGCAGCGGCACCTGAAGATGGTCCTCAGACTCAGTCTCCC AGGAGGGAACCTGCCCCAAATGCCCCAGGAGACATCGCGGCGGCATTTCCCGCTGAGAGGGACAGCTCT ACTCCATACCAAGAGATTGCTGCCGTCCCCAGTGCTGGAAGAGAGAGACAGCCGAAGGAAGAAGGACAG AAGTCCTCCTTCTCCTTCTCCAGTGGCATCGACCAGTCACCTGGAATGTCGCCAGTACCCCTCAGAGAG CCAATGAAGGCACCGCTGTGTGGAGAGGGGGACCAGCCTGGTGGTTTTGAGTCCCAAGAGAAAGAGGCT GCAGGTGGCTTTCCCCCTGCAGAGTCCAGGCAGGGGGTGGCTTCTGTGCAAGTGACCCCTGAGGCCCCT GCTGCAGCCCAGCAGGGCACAGAAAGCTCAGCGGTCTTGGAGAAGTCCCCCCTAAAACCCATGGCCCCG ATCCCACAAGATCCAGCCCCAAGAGCCTCAGACAGAGAAAGAGGCCAAGGGGAGGCGCCGCCTCAGTAT TTAACAGATGACTTGGAATTCCTCAGGGCCTGCCATCTCCCTAGGAGCAATTCAGGGGCTGCCCCAGAA GCAGAAGTGAATGCCGCTTCCCAGGAGAGCTGCCAGCAGCCAGTGGGAGCATATCTGCCGCACGCAGAG CTGCCCTGGGGCTTGCCAAGTCCTGCCCTGGTGCCAGAGGCTGGGGGCTCTGGGAAGGAGGCTCTGGAC ACCATTGATGTTCAGGGTCACCCACAGACAGGGATGCGAGGAACCAAGCCCAATCAAGTTGTCTGTGTG GCAGCAGGCGGCCAGCCCGAAGGGGGTTTGCCTGTGAGCCCTGAACCTTCCCTGCTCACTCCGACTGAG GAAGCACATCCAGCTTCAAGCCTCGCTTCATTCCCAGCTGCTCAGATTCCTATTGCTGTAGAAGAACCT GGATCATCATCCAGGGAATCAGTTTCCAAGGCTGGGATGCCAGTTTCTGCAGATGCAGCCAAAGAGGTG GTGGATGCAGGGTTGGTGGGACTGGAGAGGCAGGTGTCAGATCTTGGAAGCAAGGGAGAGCATCCAGAA GGGGACCCTGGAGAGGTTCCTGCCCCATCACCCCAGGAGAGGGGAGAGCACTTGAACACGGAGCAAAGC CATGAGGTCCAACCAGGAGTACCACCCCCTCCTCTTCCCAAGGAGCAAAGCCATGAGGTCCAACCAGGA GCACCACCCCCTCCTCTTCCCAAGGCACCAAGTGAAAGTGCCAGAGGGCCACCGGGGCCAACGGATGGA GCCAAGGTCCATGAAGATTCCACAAGCCCAGCCGTGGCTAAAGAAGGAAGCAGATCACCTGGTGACAGC CCTGGAGGAAAGGAGGAAGCCCCAGAGCCACCTGATGGTGGAGACCCAGGGAACCTGCAAGGAGAGGAC TCTCAGGCTTTCAGCAGCAAGCGTGATCCAGAAGTAGGCAAAGATGAGCTTTCAAAGCCAAGCAGTGAT GCAGAGAGCAGAGACCATCCCAGCTCACACTCAGCACAGCCACCCAGAAAGGGGGGTGCTGGGCACACG GACGGGCCCCACTCTCAGACAGCAGAGGCTGATGCATCTGGCCTACCACACAAGCTGGGTGAGGAGGAC CCCGTCCTGCCCCCTGTGCCAGATGGAGCTGGTGAGCCCACTGTTCCCGAAGGAGCCATCTGGGAGGGG TCAGGATTGCAGCCCAAATGTCCTGACACCCTTCAGAGCAGGGAAGGATTGGGAAGAATGGAGTCTTTC CTGACTTTAGAATCAGAGAAATCAGATTTTCCACCAACTCCTGTTGCAGAGGTTGCACCCAAAGCCCAG GAAGGTGAGAGCACATTGGAAATAAGGAAGATGGGCAGCTGTGATGGGGAGGGCTTGCTGACGTCCCCA GATCAACCCCGCGGGCCGGCGTGTGATGCGTCGAGACAGGAATTTCATGCTGGGGTGCCACATCCCCCC CAGGGGGAGAACTTGGCAGCAGACCTGGGGCTCACGGCACTCATCCTGGACCAAGATCAGCAGGGAATC CCATCCTGCCCAGGGGAAGGCTGGATAAGAGGAGCTGCATCCGAGTGGCCCCTACTATCTTCTGAGAAG CATCTCCAGCCATCCCAGGCACAACCAGAGACATCCATCTTTGACGTGCTCAAGGAGCAGGCCCAGCCA CCTGAAAATGGGAAAGAGACTTCTCCAAGCCATCCAGGTTTTAAGGACCAGGGAGCAGATTCTTCCCAA ATCCATGTACCTGTGGAACCTCAGGAAGATAACAACTTGCCCACTCATGGAGGACAGGAGCAGGCTTTG GGATCAGAACTTCAAAGTCAGCTCCCCAAAGGCACCCTGTCTGATACTCCAACTTCATCTCCCACTGAC ATGGTTTGGGAGAGTTCTCTGACAGAAGAGTCAGAATTGTCAGCACCAACGAGACAGAAGTTGCCTGCA CTAGGGGAGAAGCGGCCAGAGGGAGCATGCGGTGATGGTCAGTCCTCGAGGGTCTCGCCTCCAGCAGCA GATGTCTTAAAAGACTTTTCTCTTGCAGGGAACTTCAGCAGAAAGGAAACTTGCTGCACTGGGCAGGGG CCAAACAAGTCTCAACAGGCATTGGCTGATGCCTTGGAAGAAGGCAGCCAGCATGAAGAAGCATGTCAA AGGCATCCAGGAGCTTCTGAAGCAGCTGATGGTTGTTCCCCACTCTGGGGCTTGAGTAAGAGGGAGATG GCAAGTGGAAACACAGGGGAGGCCCCACCTTGTCAGCCTGACTCAGTAGCTCTCCTGGATGCAGTTCCC TGCCTGCCAGCCCTGGCGCCCGCCAGCCCCGGAGTCACACCCACCCAGGATGCCCCAGAGACAGAGGCA TGTGATGAAACCCAGGAAGGCAGGCAGCAACCAGTGCCGGCCCCGCAGCAGAAAATGGAGTGCCGGGCC ACTTCGGATGCAGAGTCCCCAAAGCTTCTTGCAAGTTTCCCATCAGCTGGGGAGCAAGGTGGTGAAGCC GGGGCTGCTGAGACTGGTGGCAGCGCTGGTGCAGGAGACCCAGGAAAGCAGCAGGCTCCGGAGAAACCT GGAGAAGCTACTTTGAGTTGTGGCCTCCTTCAGACTGAGCACTGCCTTACCTCCGGGGAGGAAGCTTCT ACCTCTGCCCTACGTGAGTCCTGCCAAGCTGAGCACCCCATGGCCAGCTGCCAGGATGCCTTGCTGCCA GCCAGAGAGCTGGGTGGGATTCCCAGGAGCACCATGGATTTTTCTACACACCAGGCTGTCCCAGACCCA AAGGAGCTCCTGCTGTCTGGGCCACCAGAAGTGGCTGCTCCTGACACCCCTTACCTGCATGTCGACAGT GCTGCCCAGAGAGGAGCAGAAGACAGTGGAGTGAAAGCTGTTTCCTCTGCAGACCCCAGAGCTCCTGGC GAAAGCCCCTGTCCTGTAGGGGAGCCCCCACTTGCCTTGGAAAATGCTGCCTCCTTGAAGCTGTTTGCT GGCTCCCTCGCCCCCCTGTTGCAACCAGGAGCTGCAGGTGGGGAAATCCCTGCAGTGCAAGCCAGCAGT GGTAGTCCCAAAGCCAGAACCACTGAGGGACCAGTGGACTCCATGCCATGCCTGGACCGGATGCCACTT CTGGCCAAGGGCAAGCAGGCAACAGGGGAAGAGAAAGCAGCAACAGCTCCAGGTGCAGGTGCCAAGGCC AGTGGGGAGGGCATGGCAGGTGATGCAGCAGGAGAGACAGAGGGCAGCATGGAGAGGATGGGAGAGCCT TCCCAGGACCCAAAGCAGGGCACATCAGGTGGTGTGGACACAAGCTCTGAGCAAATCGCCACCCTCACT GGCTTCCCAGACTTCAGGGAGCACATCGCCAAGATCTTCGAGAAGCCTGTGCTCGGAGCCCTGGCCACA CCTGGAGAAAAGGCAGGAGCTGGGAGGAGTGCAGTGGGTAAAGACCTCACCAGGCCATTGGGCCCAGAG AAGCTTCTAGATGGGCCTCCAGGAGTGGATGTCACCCTTCTCCCTGCACCTCCTGCTCGACTCCAGGTG GAGAAGAAGCAACAGTTGGCTGGAGAGGCTGAGATTTCCCATCTGGCTCTGCAAGATCCAGCTTCAGAC AAGCTTCTGGGTCCAGCAGGGCTGACCTGGGAGCGGAACTTGCCAGGTGCCGGTGTGGGGAAGGAGATG GCAGGTGTCCCACCCACACTGAGGGAAGACGAGAGGCCAGAGGGGCCTGGGGCAGCCTGGCCAGGCCTG GAAGGCCAGGCTTACTCACAGCTGGAGAGGAGCAGGCAGGAATTAGCTTCAGGTCTTCCTTCACCAGCA GCTACTCAGGAGCTCCCTGTGGAGAGAGCTGCTGCCTTCCAGGTGGCTCCCCATAGCCATGGAGAAGAG GCCGTGGCCCAAGACAGAATTCCTTCTGGAAAGCAGCACCAGGAAACATCTGCCTGCGACAGTCCACAT GGAGAAGATGGTCCCGGGGACTTTGCTCACACAGGGGTTCCAGGACATGTGCCAAGGTCCACGTGTGCC CCTTCTCCTCAGAGGGAGGTTTTGACTGTGCCTGAGGCCAACAGTGAGCCCTGGACCCTTGACACGCTT GGGGGTGAAAGGAGACCCGGAGTCACTGCTGGCATCTTGGAAATGCGAAATGCCCTGGGCAACCAGAGC ACCCCTGCACCACCAACTGGAGAAGTGGCAGACACTCCCCTGGAGCCTGGCAAGGTGGCAGGCGCTGCT GGGGAAGCAGAGGGTGACATCACCCTGAGCACAGCTGAGACACAGGCATGTGCGTCCGGTGATCTGCCT GAAGCAGGTACTACGAGGACATTCTCCGTTGTGGCAGGTGACTTGGTGCTGCCAGGAAGCTGTCAGGAC CCAGCCTGCTCTGACAAGGCTCCGGGGATGGAGGGTACAGCTGCCCTTCATGGGGACAGCCCAGCCAGG CCCCAGCAGGCTAAGGAGCAGCCAGGGCCTGAGCGCCCCATTCCAGCTGGGGATGGGAAGGTGTGCGTC TCCTCACCTCCAGAGCCTGACGAAACTCACGACCCGAAGCTGCAACATTTGGCTCCAGAAGAGCTCCAC ACTGACAGAGAGAGCCCCAGGCCTGGCCCATCCATGTTACCTTCGGTTCCTAAGAAGGATGCTCCAAGA GTCATGGATAAAGTCACTTCAGATGAGACCAGAGGTGCGGAAGGAACAGAAAGGTCAGCGAAAGATATT GGTCTTTGGAAGGCCATGATGCCTTCCTTAGATACAGACACACTGGATGTTTTGGAAAGGAGAGTAGTC CTTATACAGCATGAGTTCCTACATAAGAAAGAAGCAAATGGCCATTCCCGTTTTATGTACAGTTCACCT GTGGCAGATGATATCATCCAGCCCGCTGCCCCCGCAGACCTGGAAAGCCCAACCTTAGCTGCCTCTTCC TACCACGGTGATGTTGTTGGCCAGGTCTCTACGGATCTGATAGCCCAGAGGAGTTCCGATTCTGAAGAG GCATTTGAGACCCCGGAGTCAACGACCCCTGTCAAAGCTCCGCCAGCTCCACCCCCACCACCCCCCGAA GTCATCCCAGAACCCGAGGTCAGCACACAGCCACCCCCGGAAGAACCAGGATGTGGTTCTGAGACAGTC CCTGTCCCTGATGGCCCACGGAGCGACTCGGTGGAAGGAAGTCCCTTCCGTCCCCCGTCACACTCCTTC TCTGCCGTCTTCGATGAAGACAAGCCGATAGCCAGCAGTGGGACTTACAACTTGGACTTTGACAACATT GAGCTTGTGGATACCTTTCAGACCTTGGAGCCTCGTGCCTCAGACGCTAAGAATCAGGAGGGCAAAGTG AACACACGGAGGAAGTCCACGGATTCCGTCCCCATCTCTAAGTCTACACTGTCCCGGTCGCTCAGCCTG CAAGCCAGTGACTTTGATGGTGCTTCTTCCTCAGGCAATCCCGAGGCCGTGGCCCTTGCCCCAGATGCA TATAGCACGGGTTCCAGCAGTGCTTCTAGTACCCTTAAGCGAACTAAAAAACCGAGGCCGCCTTCCTTA AAAAAGAAACAGACCACCAAGAAACCCACAGAGACCCCCCCAGTGAAGGAGACGCAACAGGAGCCAGAT GAAGAGAGCCTTGTCCCCAGTGGGGAGAATCTAGCATCTGAGACGAAAACGGAATCTGCCAAGACGGAA GGTCCTAGCCCAGCCTTATTGGAGGAGACGCCCCTTGAGCCCGCTGTGGGGCCCAAAGCTGCCTGCCCT CTGGACTCAGAGAGTGCAGAAGGGGTTGTCCCCCCGGCTTCTGGAGGTGGCAGAGTGCAGAACTCACCC CCTGTCGGGAGGAAAACGCTGCCTCTTACCACGGCCCCGGAGGCAGGGGAGGTAACCCCATCGGATAGC GGGGGGCAAGAGGACTCTCCAGCCAAAGGGCTCTCCGTAAGGCTGGAGTTTGACTATTCTGAGGACAAG AGTAGTTGGGACAACCAGCAGGAAAACCCCCCTCCTACCAAAAAGATAGGCAAAAAGCCAGTTGCCAAA ATGCCCCTGAGGAGGCCAAAGATGAAAAAGACACCCGAGAAACTTGACAACACTCCTGCCTCACCTCCC AGATCCCCTGCTGAACCCAATGACATCCCCATTGCTAAAGGTACTTACACCTTTGATATTGACAAGTGG GATGACCCCAATTTTAACCCTTTTTCTTCCACCTCAAAAATGCAGGAGTCTCCCAAACTGCCCCAACAA TCATACAACTTTGACCCAGACACCTGTGATGAGTCCGTTGACCCCTTTAAGACATCCTCTAAGACCCCC AGCTCACCTTCTAAATCCCCAGCCTCCTTTGAGATCCCAGCCAGTGCTATGGAAGCCAATGGAGTGGAC GGGGATGGGCTAAACAAGCCCGCCAAGAAGAAGAAGACGCCCCTAAAGACTGACACATTTAGGGTGAAA AAGTCGCCAAAACGGTCTCCTCTCTCTGATCCACCTTCCCAGGACCCCACCCCAGCTGCTACACCAGAA ACACCACCAGTGATCTCTGCGGTGGTCCACGCCACAGATGAGGAAAAGCTGGCGGTCACCAACCAGAAG TGGACGTGCATGACAGTGGACCTAGAGGCTGACAAACAGGACTACCCGCAGCCCTCGGACCTGTCCACC TTTGTAAACGAGACCAAATTCAGTTCACCCACTGAGGAGTTGGATTACAGAAACTCCTATGAAATTGAA TATATGGAGAAAATTGGCTCCTCCTTACCTCAGGACGACGATGCCCCGAAGAAGCAGGCCTTGTACCTT ATGTTTGACACTTCTCAGGAGAGCCCTGTCAAGTCATCTCCCGTCCGCATGTCAGAGTCCCCGACGCCG TGTTCAGGGTCAAGTTTTGAAGAGACTGAAGCCCTTGTGAACACTGCTGCGAAAAACCAGCATCCTGTC CCACGAGGACTGGCCCCTAACCAAGAGTCACACTTGCAGGTGCCAGAGAAATCCTCCCAGAAGGAGCTG GAGGCCATGGGCTTGGGCACCCCTTCAGAAGCGATTGAAATTAGAGAGGCTGCTCACCCAACAGACGTC TCCATCTCCAAAACAGCCTTGTACTCCCGCATCGGGACCGCTGAGGTGGAGAAACCTGCAGGCCTTCTG TTCCAGCAGCCCGACCTGGACTCTGCCCTCCAGATCGCCAGAGCAGAGATCATAACCAAGGAGAGAGAG GTCTCAGAATGGAAAGATAAATATGAAGAAAGCAGGCGGGAAGTGATGGAAATGAGGAAAATAGTGGCC GAGTATGAGAAGACCATCGCTCAGATGATAGAGGACGAACAGAGAGAGAAGTCAGTCTCCCACCAGACG GTGCAGCAGCTGGTTCTGGAGAAGGAGCAAGCCCTGGCCGACCTGAACTCCGTGGAGAAGTCTCTGGCC GACCTCTTCAGAAGATATGAGAAGATGAAGGAGGTCCTAGAAGGCTTCCGCAAGAATGAAGAGGTGTTG AAGAGATGTGCGCAGGAGTACCTGTCCCGGGTGAAGAAGGAGGAGCAGAGGTACCAGGCCCTGAAGGTG CACGCGGAGGAGAAACTGGACAGGGCCAATGCTGAGATTGCTCAGGTTCGAGGCAAGGCCCAGCAGGAG CAAGCCGCCCACCAGGCCAGCCTGCGGAAGGAGCAGCTGCGAGTGGACGCCCTGGAAAGGACGCTGGAG CAGAAGAATAAAGAAATAGAAGAACTCACCAAGATTTGTGACGAACTGATTGCCAAAATGGGGAAAAGC AGCGGACCGACGCGTACGCGGCCGCTCGAG - GFP Tag - GTTTAAAC >Peptide sequence encoded by RG240259
Blue=ORF Red=Cloning site Green=Tag(s) MGNENSTSDNQRTLSAQTPRSAQPPGNSQNIKRKQQDTPGSPDHRDASSIGSVGLGGFCTASESSASLD PCLVSPEVTEPRKDPQGARGPEGSLLPSPPPSQEREHPSSSMPFAECPPEGCLASPAAAPEDGPQTQSP RREPAPNAPGDIAAAFPAERDSSTPYQEIAAVPSAGRERQPKEEGQKSSFSFSSGIDQSPGMSPVPLRE PMKAPLCGEGDQPGGFESQEKEAAGGFPPAESRQGVASVQVTPEAPAAAQQGTESSAVLEKSPLKPMAP IPQDPAPRASDRERGQGEAPPQYLTDDLEFLRACHLPRSNSGAAPEAEVNAASQESCQQPVGAYLPHAE LPWGLPSPALVPEAGGSGKEALDTIDVQGHPQTGMRGTKPNQVVCVAAGGQPEGGLPVSPEPSLLTPTE EAHPASSLASFPAAQIPIAVEEPGSSSRESVSKAGMPVSADAAKEVVDAGLVGLERQVSDLGSKGEHPE GDPGEVPAPSPQERGEHLNTEQSHEVQPGVPPPPLPKEQSHEVQPGAPPPPLPKAPSESARGPPGPTDG AKVHEDSTSPAVAKEGSRSPGDSPGGKEEAPEPPDGGDPGNLQGEDSQAFSSKRDPEVGKDELSKPSSD AESRDHPSSHSAQPPRKGGAGHTDGPHSQTAEADASGLPHKLGEEDPVLPPVPDGAGEPTVPEGAIWEG SGLQPKCPDTLQSREGLGRMESFLTLESEKSDFPPTPVAEVAPKAQEGESTLEIRKMGSCDGEGLLTSP DQPRGPACDASRQEFHAGVPHPPQGENLAADLGLTALILDQDQQGIPSCPGEGWIRGAASEWPLLSSEK HLQPSQAQPETSIFDVLKEQAQPPENGKETSPSHPGFKDQGADSSQIHVPVEPQEDNNLPTHGGQEQAL GSELQSQLPKGTLSDTPTSSPTDMVWESSLTEESELSAPTRQKLPALGEKRPEGACGDGQSSRVSPPAA DVLKDFSLAGNFSRKETCCTGQGPNKSQQALADALEEGSQHEEACQRHPGASEAADGCSPLWGLSKREM ASGNTGEAPPCQPDSVALLDAVPCLPALAPASPGVTPTQDAPETEACDETQEGRQQPVPAPQQKMECRA TSDAESPKLLASFPSAGEQGGEAGAAETGGSAGAGDPGKQQAPEKPGEATLSCGLLQTEHCLTSGEEAS TSALRESCQAEHPMASCQDALLPARELGGIPRSTMDFSTHQAVPDPKELLLSGPPEVAAPDTPYLHVDS AAQRGAEDSGVKAVSSADPRAPGESPCPVGEPPLALENAASLKLFAGSLAPLLQPGAAGGEIPAVQASS GSPKARTTEGPVDSMPCLDRMPLLAKGKQATGEEKAATAPGAGAKASGEGMAGDAAGETEGSMERMGEP SQDPKQGTSGGVDTSSEQIATLTGFPDFREHIAKIFEKPVLGALATPGEKAGAGRSAVGKDLTRPLGPE KLLDGPPGVDVTLLPAPPARLQVEKKQQLAGEAEISHLALQDPASDKLLGPAGLTWERNLPGAGVGKEM AGVPPTLREDERPEGPGAAWPGLEGQAYSQLERSRQELASGLPSPAATQELPVERAAAFQVAPHSHGEE AVAQDRIPSGKQHQETSACDSPHGEDGPGDFAHTGVPGHVPRSTCAPSPQREVLTVPEANSEPWTLDTL GGERRPGVTAGILEMRNALGNQSTPAPPTGEVADTPLEPGKVAGAAGEAEGDITLSTAETQACASGDLP EAGTTRTFSVVAGDLVLPGSCQDPACSDKAPGMEGTAALHGDSPARPQQAKEQPGPERPIPAGDGKVCV SSPPEPDETHDPKLQHLAPEELHTDRESPRPGPSMLPSVPKKDAPRVMDKVTSDETRGAEGTERSAKDI GLWKAMMPSLDTDTLDVLERRVVLIQHEFLHKKEANGHSRFMYSSPVADDIIQPAAPADLESPTLAASS YHGDVVGQVSTDLIAQRSSDSEEAFETPESTTPVKAPPAPPPPPPEVIPEPEVSTQPPPEEPGCGSETV PVPDGPRSDSVEGSPFRPPSHSFSAVFDEDKPIASSGTYNLDFDNIELVDTFQTLEPRASDAKNQEGKV NTRRKSTDSVPISKSTLSRSLSLQASDFDGASSSGNPEAVALAPDAYSTGSSSASSTLKRTKKPRPPSL KKKQTTKKPTETPPVKETQQEPDEESLVPSGENLASETKTESAKTEGPSPALLEETPLEPAVGPKAACP LDSESAEGVVPPASGGGRVQNSPPVGRKTLPLTTAPEAGEVTPSDSGGQEDSPAKGLSVRLEFDYSEDK SSWDNQQENPPPTKKIGKKPVAKMPLRRPKMKKTPEKLDNTPASPPRSPAEPNDIPIAKGTYTFDIDKW DDPNFNPFSSTSKMQESPKLPQQSYNFDPDTCDESVDPFKTSSKTPSSPSKSPASFEIPASAMEANGVD GDGLNKPAKKKKTPLKTDTFRVKKSPKRSPLSDPPSQDPTPAATPETPPVISAVVHATDEEKLAVTNQK WTCMTVDLEADKQDYPQPSDLSTFVNETKFSSPTEELDYRNSYEIEYMEKIGSSLPQDDDAPKKQALYL MFDTSQESPVKSSPVRMSESPTPCSGSSFEETEALVNTAAKNQHPVPRGLAPNQESHLQVPEKSSQKEL EAMGLGTPSEAIEIREAAHPTDVSISKTALYSRIGTAEVEKPAGLLFQQPDLDSALQIARAEIITKERE VSEWKDKYEESRREVMEMRKIVAEYEKTIAQMIEDEQREKSVSHQTVQQLVLEKEQALADLNSVEKSLA DLFRRYEKMKEVLEGFRKNEEVLKRCAQEYLSRVKKEEQRYQALKVHAEEKLDRANAEIAQVRGKAQQE QAAHQASLRKEQLRVDALERTLEQKNKEIEELTKICDELIAKMGKS SGPTRTRPLEMESDESGLPAMEIECRITGTLNGVEFELVGGGEGTPEQGRMTNKMKSTKGALTFSPYLL SHVMGYGFYHFGTYPSGYENPFLHAINNGGYTNTRIEKYEDGGVLHVSFSYRYEAGRVIGDFKVMGTGF PEDSVIFTDKIIRSNATVEHLHPMGDNDLDGSFTRTFSLRDGGYYSSVVDSHMHFKSAIHPSILQNGGP MFAFRRVEEDHSNTELGIVEYQHAFKTPDADAGEERV |
| Restriction Sites |
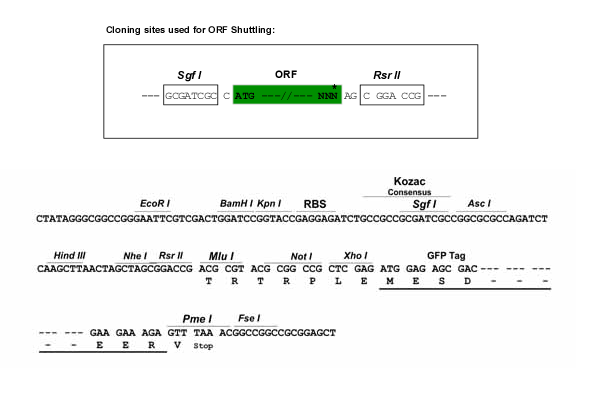
SgfI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_001291877 |
| ORF Size | 8625 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reference Data | |
| RefSeq | NM_001291877.1, NP_001278806.1 |
| RefSeq Size | 9498 bp |
| RefSeq ORF | 8628 bp |
| Locus ID | 10579 |
| MW | 302.9 kDa |
| Gene Summary | Transforming acidic coiled-coil proteins are a conserved family of centrosome- and microtubule-interacting proteins that are implicated in cancer. This gene encodes a protein that concentrates at centrosomes throughout the cell cycle. This gene lies within a chromosomal region associated with tumorigenesis. Expression of this gene is induced by erythropoietin and is thought to affect the progression of breast tumors. Several transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Jul 2008] |
Documents
| Product Manuals |
| FAQs |
| SDS |

{kind=link}