
 United States
United States
 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
NOLC1 (NM_004741) Human Tagged ORF Clone
CAT#: RC200356

NOLC1 (Myc-DDK-tagged)-Human nucleolar and coiled-body phosphoprotein 1 (NOLC1)
ORF Plasmid: tGFP
"NM_004741" in other vectors (4)
Need custom modification / cloning service?
Get a free quote
CNY 5,128.00
CNY 7,410.00
Product images

 using anti-DDK antibody (Cat# <a href='/catalog/antibodies/tag-antibodies/ta50011-100-clone-oti4c5-anti-ddk-flag-monoclonal-antibody'>TA50011-100</a>). Left: Cell lysates from un-transfected HEK293T cells; Right: Cell lysates from HEK293T cells transfected with RC200356 using transfection reagent MegaTran 2.0 (Cat# <a href='/catalog/others/transfection-reagents/tt210002-megatran-20-plasmid-dna-transfection-reagent-05-ml'>TT210002</a>).")
. The protein was produced from HEK293T cells transfected with NOLC1 cDNA clone (Cat# RC200356) using MegaTran 2.0 (Cat# <a href='/catalog/others/transfection-reagents/tt210002-megatran-20-plasmid-dna-transfection-reagent-05-ml'>TT210002</a>).")
CNY 300.00
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Synonyms | NOPP130; NOPP140; NS5ATP13; P130; Srp40 |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC200356 ORF sequence
Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGCGGACGCCGGCATTCGCCGCGTGGTTCCCAGCGACCTGTATCCCCTCGTGCTCGGCTTCCTGCGCG ATAACCAACTCTCAGAGGTGGCCAATAAGTTCGCCAAAGCGACAGGAGCTACACAGCAGGATGCCAATGC CTCTTCCCTCTTAGACATCTATAGCTTCTGGCTCAACAGGTCTGCCAAGGTCCCAGAGCGAAAGTTACAG GCAAATGGACCAGTGGCTAAGAAAGCTAAGAAGAAGGCCTCATCCAGTGACAGTGAGGACAGCAGCGAGG AGGAGGAGGAAGTTCAAGGGCCTCCAGCAAAGAAGGCTGCTGTACCTGCCAAGCGAGTCGGTCTGCCTCC TGGGAAGGCTGCAGCCAAAGCATCAGAGAGTAGCAGCAGTGAAGAGTCCAGTGATGATGATGATGAGGAG GACCAAAAGAAACAGCCTGTCCAGAAGGGAGTTAAGCCCCAAGCCAAGGCAGCCAAAGCTCCTCCTAAGA AGGCCAAGAGCTCTGATTCTGATTCTGACTCAAGCTCCGAGGATGAGCCACCAAAGAACCAGAAGCCAAA GATAACACCTGTGACAGTTAAAGCTCAGACTAAAGCCCCTCCCAAACCAGCTCGAGCAGCACCTAAAATA GCCAATGGTAAAGCAGCCAGTAGCAGCAGTAGCAGCAGCAGCAGCAGTAGCAGTGATGACTCAGAGGAGG AGAAGGCAGCAGCCACCCCCAAGAAGACTGTACCTAAAAAGCAAGTTGTGGCCAAGGCCCCAGTGAAAGC AGCTACCACCCCTACCCGGAAGAGTTCTAGCAGTGAGGATTCCTCCAGTGACGAGGAAGAGGAGCAAAAA AAACCCATGAAAAATAAACCAGGTCCCTACAGTTCAGTCCCCCCGCCTTCTGCTCCCCCACCAAAGAAGT CTCTGGGAACCCAGCCTCCCAAGAAGGCTGTGGAGAAGCAGCAGCCTGTGGAAAGCAGTGAAGACAGCAG TGATGAGTCTGATTCAAGTTCTGAAGAAGAGAAGAAACCCCCAACTAAGGCAGTAGTCTCTAAAGCAACC ACTAAACCACCTCCAGCAAAGAAAGCAGCAGAGAGCTCTTCAGACAGCTCAGACTCTGACAGCTCTGAGG ATGATGAAGCTCCTTCTAAGCCAGCTGGTACCACCAAGAATTCTTCAAATAAGCCAGCTGTCACCACCAA GTCACCTGCAGTGAAGCCAGCTGCAGCCCCCAAGCAACCTGTGGGCGGTGGCCAGAAGCTTCTGACGAGA AAGGCTGACAGCAGCTCCAGTGAGGAAGAGAGCAGCTCCAGTGAGGAGGAGAAGACAAAGAAGATGGTGG CCACCACTAAGCCCAAGGCGACTGCCAAAGCAGCTCTATCTCTGCCTGCCAAGCAGGCTCCTCAGGGTAG TAGGGACAGCAGCTCTGATTCAGACAGCTCCAGCAGTGAGGAGGAGGAAGAGAAGACATCTAAGTCTGCA GTTAAGAAGAAGCCACAGAAGGTAGCAGGAGGTGCAGCCCCTTCCAAGCCAGCCTCTGCAAAGAAAGGAA AGGCTGAGAGCAGCAACAGTTCTTCTTCTGATGACTCCAGTGAGGAAGAGGAAGAGAAGCTCAAGGGCAA GGGCTCTCCAAGACCACAAGCCCCCAAGGCCAATGGCACCTCTGCACTGACTGCCCAGAATGGAAAAGCA GCTAAGAACAGTGAGGAGGAGGAAGAAGAAAAGAAAAAGGCGGCAGTGGTAGTTTCCAAATCAGGTTCAT TAAAGAAGCGGAAGCAGAATGAGGCTGCCAAGGAGGCAGAGACTCCTCAGGCCAAGAAGATAAAGCTTCA GACCCCTAACACATTTCCAAAAAGGAAGAAAGGAGAAAAAAGGGCATCATCCCCATTCCGAAGGGTCAGG GAGGAGGAAATTGAGGTGGATTCACGAGTTGCGGACAACTCCTTTGATGCCAAGCGAGGTGCAGCCGGAG ACTGGGGAGAGCGAGCCAATCAGGTTTTGAAGTTCACCAAAGGCAAGTCCTTTCGGCATGAGAAAACCAA GAAGAAGCGGGGCAGCTACCGGGGAGGCTCAATCTCTGTCCAGGTCAATTCTATTAAGTTTGACAGCGAG AGCGGACCGACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCC TGGATTACAAGGATGACGACGATAAGGTTTAA >RC200356 protein sequence
Red=Cloning site Green=Tags(s) MADAGIRRVVPSDLYPLVLGFLRDNQLSEVANKFAKATGATQQDANASSLLDIYSFWLNRSAKVPERKLQ ANGPVAKKAKKKASSSDSEDSSEEEEEVQGPPAKKAAVPAKRVGLPPGKAAAKASESSSSEESSDDDDEE DQKKQPVQKGVKPQAKAAKAPPKKAKSSDSDSDSSSEDEPPKNQKPKITPVTVKAQTKAPPKPARAAPKI ANGKAASSSSSSSSSSSSDDSEEEKAAATPKKTVPKKQVVAKAPVKAATTPTRKSSSSEDSSSDEEEEQK KPMKNKPGPYSSVPPPSAPPPKKSLGTQPPKKAVEKQQPVESSEDSSDESDSSSEEEKKPPTKAVVSKAT TKPPPAKKAAESSSDSSDSDSSEDDEAPSKPAGTTKNSSNKPAVTTKSPAVKPAAAPKQPVGGGQKLLTR KADSSSSEEESSSSEEEKTKKMVATTKPKATAKAALSLPAKQAPQGSRDSSSDSDSSSSEEEEEKTSKSA VKKKPQKVAGGAAPSKPASAKKGKAESSNSSSSDDSSEEEEEKLKGKGSPRPQAPKANGTSALTAQNGKA AKNSEEEEEEKKKAAVVVSKSGSLKKRKQNEAAKEAETPQAKKIKLQTPNTFPKRKKGEKRASSPFRRVR EEEIEVDSRVADNSFDAKRGAAGDWGERANQVLKFTKGKSFRHEKTKKKRGSYRGGSISVQVNSIKFDSE SGPTRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
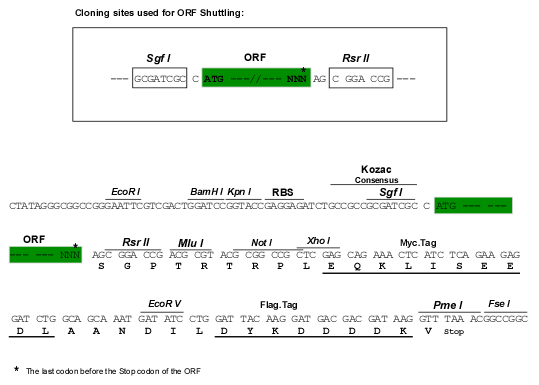
SgfI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_004741 |
| ORF Size | 2100 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Note | Plasmids are not sterile. For experiments where strict sterility is required, filtration with 0.22um filter is required. |
| Reference Data | |
| RefSeq | NM_004741.5 |
| RefSeq Size | 3947 bp |
| RefSeq ORF | 2100 bp |
| Locus ID | 9221 |
| UniProt ID | Q14978 |
| Domains | SRP40_C |
| Protein Families | Stem cell - Pluripotency |
| MW | 73.7 kDa |
| Gene Summary | Nucleolar protein that acts as a regulator of RNA polymerase I by connecting RNA polymerase I with enzymes responsible for ribosomal processing and modification (PubMed:10567578, PubMed:26399832). Required for neural crest specification: following monoubiquitination by the BCR(KBTBD8) complex, associates with TCOF1 and acts as a platform to connect RNA polymerase I with enzymes responsible for ribosomal processing and modification, leading to remodel the translational program of differentiating cells in favor of neural crest specification (PubMed:26399832). Involved in nucleologenesis, possibly by playing a role in the maintenance of the fundamental structure of the fibrillar center and dense fibrillar component in the nucleolus (PubMed:9016786). It has intrinsic GTPase and ATPase activities (PubMed:9016786).[UniProtKB/Swiss-Prot Function] |
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| RC200356L3 | Lenti ORF clone of Human nucleolar and coiled-body phosphoprotein 1 (NOLC1), Myc-DDK-tagged |
CNY 9,310.00 |
|
| RC200356L4 | Lenti ORF clone of Human nucleolar and coiled-body phosphoprotein 1 (NOLC1), mGFP tagged |
CNY 9,310.00 |
|
| RG200356 | NOLC1 (tGFP-tagged) - Human nucleolar and coiled-body phosphoprotein 1 (NOLC1) |
CNY 6,728.00 |
|
| SC321368 | NOLC1 (untagged)-Human nucleolar and coiled-body phosphoprotein 1 (NOLC1) |
CNY 5,128.00 |

{kind=link}