
 United States
United States
 Germany
Germany
 Japan
Japan
 United Kingdom
United Kingdom
 China
China
PEX1 (NM_000466) Human Tagged ORF Clone
CAT#: RC207612

PEX1 (Myc-DDK-tagged)-Human peroxisomal biogenesis factor 1 (PEX1)
ORF Plasmid: tGFP
"NM_000466" in other vectors (6)
Need custom modification / cloning service?
Get a free quote
CNY 8,936.00
Product images

 using anti-DDK antibody (Cat# <a href='/catalog/antibodies/tag-antibodies/ta50011-100/clone-oti4c5-anti-ddk-flag-monoclonal-antibody'>TA50011-100</a>). Left: Cell lysates from un-transfected HEK293T cells; Right: Cell lysates from HEK293T cells transfected with RC207612 using transfection reagent MegaTran 2.0 (Cat# <a href='/catalog/others/transfection-reagents/tt210002/megatran-20-plasmid-dna-transfection-reagent-05-ml'>TT210002</a>).")
CNY 300.00
Specifications
| Product Data | |
| Type | Human Tagged ORF Clone |
| Tag | Myc-DDK |
| Synonyms | HMLR1; PBD1A; PBD1B; ZWS; ZWS1 |
| Vector | pCMV6-Entry |
| E. coli Selection | Kanamycin (25 ug/mL) |
| Mammalian Cell Selection | Neomycin |
| Sequence Data |
>RC207612 ORF sequence
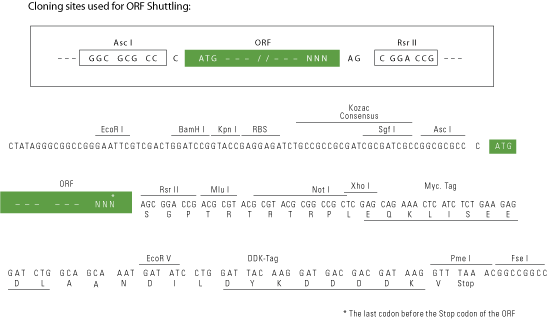
Red=Cloning site Blue=ORF Green=Tags(s) CTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCCGCCGCGATCGCCGGCGC GCCC ATGTGGGGCAGCGATCGCCTGGCGGGTGCTGGGGGAGGCGGGGCGGCAGTGACTGTGGCCTTCACCAACG CTCGCGACTGCTTCCTCCACCTGCCGCGGCGTCTCGTGGCCCAGCTGCATCTGCTGCAGAATCAAGCTAT AGAAGTGGTCTGGAGTCACCAGCCTGCATTCTTGAGCTGGGTGGAAGGCAGGCATTTTAGTGATCAAGGT GAAAATGTGGCTGAAATTAACAGACAAGTTGGTCAAAAACTTGGACTCTCAAATGGGGGACAGGTATTTC TCAAGCCATGTTCCCATGTGGTATCTTGTCAACAAGTTGAGGTGGAACCCCTCTCAGCAGATGATTGGGA GATACTGGAGCTGCATGCTGTTTCCCTTGAACAACATCTTCTAGATCAAATTCGAATAGTTTTTCCAAAA GCCATTTTTCCTGTTTGGGTTGATCAACAAACGTACATATTTATCCAAATTGTTGCACTAATACCAGCTG CCTCTTATGGAAGGCTGGAAACTGACACCAAACTCCTTATTCAGCCAAAGACACGCCGAGCCAAAGAGAA TACATTTTCAAAAGCTGATGCTGAATATAAAAAACTTCATAGTTATGGAAGAGACCAGAAAGGAATGATG AAAGAACTTCAAACCAAGCAACTTCAGTCAAATACTGTGGGAATCACTGAATCTAATGAAAACGAGTCAG AGATTCCAGTTGACTCATCATCAGTAGCAAGTTTATGGACTATGATAGGAAGCATTTTTTCCTTTCAATC TGAGAAGAAACAAGAGACATCTTGGGGTTTAACTGAAATCAATGCATTCAAAAATATGCAGTCAAAGGTT GTTCCTCTAGACAATATTTTCAGAGTATGCAAATCTCAACCTCCTAGTATATATAACGCGTCAGCAACCT CTGTTTTTCATAAACACTGTGCCATTCATGTATTTCCATGGGACCAGGAATATTTTGATGTAGAGCCCAG CTTTACTGTGACATATGGAAAGCTAGTTAAGCTACTTTCTCCAAAGCAACAGCAAAGTAAAACAAAACAA AATGTGTTATCACCTGAAAAAGAGAAGCAGATGTCAGAGCCACTAGATCAAAAAAAAATTAGGTCAGATC ATAATGAAGAAGATGAGAAGGCCTGTGTGCTACAAGTAGTCTGGAATGGACTTGAAGAATTGAACAATGC CATCAAATATACCAAAAATGTAGAAGTTCTCCATCTTGGGAAAGTCTGGATTCCAGATGACCTGAGGAAG AGACTAAATATAGAAATGCATGCCGTAGTCAGGATAACTCCAGTGGAAGTTACCCCTAAAATTCCAAGAT CTCTAAAGTTACAACCTAGAGAGAATTTACCTAAAGACATAAGTGAAGAAGACATAAAAACTGTATTTTA TTCATGGCTACAGCAGTCTACTACCACCATGCTTCCTTTGGTAATATCAGAGGAAGAATTTATTAAGCTG GAAACTAAAGATGGACTGAAGGAATTTTCTCTGAGTATAGTTCATTCTTGGGAAAAAGAAAAAGATAAAA ATATTTTTCTGTTGAGTCCCAATTTGCTGCAGAAGACTACAATACAAGTCCTTCTAGATCCTATGGTAAA AGAAGAAAACAGTGAGGAAATTGACTTTATTCTTCCTTTTTTAAAGCTGAGCTCTTTGGGAGGAGTGAAT TCCTTAGGCGTATCCTCCTTGGAGCACATCACTCACAGCCTCCTGGGACGCCCTTTGTCTCGGCAGCTGA TGTCTCTTGTTGCAGGACTTAGGAATGGAGCTCTTTTACTCACAGGAGGAAAGGGAAGTGGAAAATCAAC TTTAGCCAAAGCAATCTGTAAAGAAGCATTTGACAAACTGGATGCCCATGTGGAGAGAGTTGACTGTAAA GCTTTACGAGGAAAAAGGCTTGAAAACATACAAAAAACCCTAGAGGTGGCTTTCTCAGAGGCAGTGTGGA TGCAGCCATCTGTTGTCCTGCTGGATGACCTTGACCTCATTGCTGGACTGCCTGCTGTCCCGGAACATGA GCACAGTCCTGATGCGGTGCAGAGCCAGCGGCTTGCTCATGCTTTGAATGATATGATAAAAGAGTTTATC TCCATGGGAAGTTTGGTTGCACTGATTGCCACAAGTCAGTCTCAGCAATCTCTACATCCTTTACTTGTTT CTGCTCAAGGAGTTCACATATTTCAGTGCGTCCAACACATTCAGCCTCCTAATCAGGAACAAAGATGTGA AATTCTGTGTAATGTAATAAAAAATAAATTGGACTGTGATATAAACAAGTTCACCGATCTTGACCTGCAG CATGTAGCTAAAGAAACTGGAGGGTTTGTGGCTAGAGATTTTACAGTACTTGTGGATCGAGCCATACATT CTCGACTCTCTCGTCAGAGTATATCCACCAGAGAAAAATTAGTTTTAACAACATTGGACTTCCAAAAGGC TCTCCGCGGATTTCTTCCTGCGTCTTTGCGAAGTGTCAACCTGCATAAACCTAGAGACCTGGGTTGGGAC AAGATTGGTGGGTTACATGAAGTTAGGCAGATACTCATGGATACTATCCAGTTACCTGCCAAGTATCCAG AATTATTTGCAAACTTGCCCATACGACAAAGAACAGGAATACTGTTGTATGGTCCGCCTGGAACAGGAAA AACCTTACTAGCTGGGGTAATTGCACGAGAGAGTAGAATGAATTTTATAAGTGTCAAGGGGCCAGAGTTA CTCAGCAAATACATTGGAGCAAGTGAACAAGCTGTTCGGGATATTTTTATTAGAGCACAGGCTGCAAAGC CCTGCATTCTTTTCTTTGATGAATTTGAATCCATTGCTCCTCGGCGGGGTCATGATAATACAGGAGTTAC AGACCGAGTAGTTAACCAGTTGCTGACTCAGTTGGATGGAGTAGAAGGCTTACAGGGTGTTTATGTATTG GCTGCTACTAGTCGCCCTGACTTGATTGACCCTGCCCTGCTTAGGCCTGGTCGACTAGATAAATGTGTAT ACTGTCCTCCTCCTGATCAGGTGTCACGTCTTGAAATTTTAAATGTCCTCAGTGACTCTCTACCTCTGGC AGATGATGTTGACCTTCAGCATGTAGCATCAGTAACTGACTCCTTTACTGGAGCTGATCTGAAAGCTTTA CTTTACAATGCCCAATTGGAGGCCTTACATGGAATGCTGCTCTCGAGTGGACTCCAGGATGGAAGTTCCA GCTCTGATAGTGACCTAAGTCTGTCTTCAATGGTCTTTCTTAACCATAGCAGTGGCTCTGACGATTCAGC TGGAGATGGAGAATGTGGCTTAGATCAGTCCCTTGTTTCTTTAGAGATGTCCGAGATCCTTCCAGATGAA TCAAAATTCAATATGTACCGGCTCTACTTTGGAAGCTCTTATGAATCAGAACTTGGAAATGGAACCTCTT CTGATTTGAGCTCACAATGTCTCTCTGCACCAAGCTCCATGACTCAGGATTTGCCTGGAGTTCCTGGGAA AGACCAGTTGTTTTCACAGCCTCCAGTGTTAAGGACAGCTTCACAAGAGGGTTGCCAAGAACTTACACAA GAACAAAGAGATCAACTGAGGGCAGATATCAGTATTATCAAAGGCAGATACCGGAGCCAAAGTGGAGAGG ACGAATCCATGAACCAACCAGGACCAATCAAAACCAGACTGGCTATTAGTCAGTCACATTTAATGACTGC ACTTGGTCACACAAGACCATCCATTAGTGAAGATGACTGGAAGAATTTTGCTGAGCTATATGAAAGCTTT CAAAATCCAAAGAGGAGAAAAAATCAAAGTGGAACAATGTTTCGACCTGGACAGAAAGTAACTTTAGCA AGCGGACCGACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCC TGGATTACAAGGATGACGACGATAAGGTTTAA >RC207612 protein sequence
Red=Cloning site Green=Tags(s) MWGSDRLAGAGGGGAAVTVAFTNARDCFLHLPRRLVAQLHLLQNQAIEVVWSHQPAFLSWVEGRHFSDQG ENVAEINRQVGQKLGLSNGGQVFLKPCSHVVSCQQVEVEPLSADDWEILELHAVSLEQHLLDQIRIVFPK AIFPVWVDQQTYIFIQIVALIPAASYGRLETDTKLLIQPKTRRAKENTFSKADAEYKKLHSYGRDQKGMM KELQTKQLQSNTVGITESNENESEIPVDSSSVASLWTMIGSIFSFQSEKKQETSWGLTEINAFKNMQSKV VPLDNIFRVCKSQPPSIYNASATSVFHKHCAIHVFPWDQEYFDVEPSFTVTYGKLVKLLSPKQQQSKTKQ NVLSPEKEKQMSEPLDQKKIRSDHNEEDEKACVLQVVWNGLEELNNAIKYTKNVEVLHLGKVWIPDDLRK RLNIEMHAVVRITPVEVTPKIPRSLKLQPRENLPKDISEEDIKTVFYSWLQQSTTTMLPLVISEEEFIKL ETKDGLKEFSLSIVHSWEKEKDKNIFLLSPNLLQKTTIQVLLDPMVKEENSEEIDFILPFLKLSSLGGVN SLGVSSLEHITHSLLGRPLSRQLMSLVAGLRNGALLLTGGKGSGKSTLAKAICKEAFDKLDAHVERVDCK ALRGKRLENIQKTLEVAFSEAVWMQPSVVLLDDLDLIAGLPAVPEHEHSPDAVQSQRLAHALNDMIKEFI SMGSLVALIATSQSQQSLHPLLVSAQGVHIFQCVQHIQPPNQEQRCEILCNVIKNKLDCDINKFTDLDLQ HVAKETGGFVARDFTVLVDRAIHSRLSRQSISTREKLVLTTLDFQKALRGFLPASLRSVNLHKPRDLGWD KIGGLHEVRQILMDTIQLPAKYPELFANLPIRQRTGILLYGPPGTGKTLLAGVIARESRMNFISVKGPEL LSKYIGASEQAVRDIFIRAQAAKPCILFFDEFESIAPRRGHDNTGVTDRVVNQLLTQLDGVEGLQGVYVL AATSRPDLIDPALLRPGRLDKCVYCPPPDQVSRLEILNVLSDSLPLADDVDLQHVASVTDSFTGADLKAL LYNAQLEALHGMLLSSGLQDGSSSSDSDLSLSSMVFLNHSSGSDDSAGDGECGLDQSLVSLEMSEILPDE SKFNMYRLYFGSSYESELGNGTSSDLSSQCLSAPSSMTQDLPGVPGKDQLFSQPPVLRTASQEGCQELTQ EQRDQLRADISIIKGRYRSQSGEDESMNQPGPIKTRLAISQSHLMTALGHTRPSISEDDWKNFAELYESF QNPKRRKNQSGTMFRPGQKVTLA SGPTRTRPLEQKLISEEDLAANDILDYKDDDDKV |
| Chromatograms |
CHROMATOGRAMS
 Sequencher program is needed, download here. |
| Restriction Sites |
AscI-RsrII
Cloning Scheme for this gene
Plasmid Map

|
| ACCN | NM_000466 |
| ORF Size | 3849 bp |
| OTI Disclaimer | The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info |
| OTI Annotation | This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. |
| Product Components | The ORF clone is ion-exchange column purified and shipped in a 2D barcoded Matrix tube containing 10ug of transfection-ready, dried plasmid DNA (reconstitute with 100 ul of water). |
| Reconstitution | 1. Centrifuge at 5,000xg for 5min. 2. Carefully open the tube and add 100ul of sterile water to dissolve the DNA. 3. Close the tube and incubate for 10 minutes at room temperature. 4. Briefly vortex the tube and then do a quick spin (less than 5000xg) to concentrate the liquid at the bottom. 5. Store the suspended plasmid at -20°C. The DNA is stable for at least one year from date of shipping when stored at -20°C. |
| Reference Data | |
| RefSeq | NM_000466.1, NP_000457.1 |
| RefSeq Size | 4390 bp |
| RefSeq ORF | 3852 bp |
| Locus ID | 5189 |
| UniProt ID | O43933 |
| Domains | AAA, AAA |
| Protein Families | Druggable Genome |
| MW | 142.9 kDa |
| Gene Summary | This gene encodes a member of the AAA ATPase family, a large group of ATPases associated with diverse cellular activities. This protein is cytoplasmic but is often anchored to a peroxisomal membrane where it forms a heteromeric complex and plays a role in the import of proteins into peroxisomes and peroxisome biogenesis. Mutations in this gene have been associated with complementation group 1 peroxisomal disorders such as neonatal adrenoleukodystrophy, infantile Refsum disease, and Zellweger syndrome. Alternatively spliced transcript variants have been found for this gene. [provided by RefSeq, Sep 2013] |
Documents
| Product Manuals |
| FAQs |
| SDS |
Resources
Other Versions
| SKU | Description | Size | Price |
|---|---|---|---|
| RC207612L1 | Lenti ORF clone of Human peroxisomal biogenesis factor 1 (PEX1), Myc-DDK-tagged |
CNY 11,336.00 |
|
| RC207612L2 | Lenti ORF clone of Human peroxisomal biogenesis factor 1 (PEX1), mGFP tagged |
CNY 14,730.00 |
|
| RC207612L3 | Lenti ORF clone of Human peroxisomal biogenesis factor 1 (PEX1), Myc-DDK-tagged |
CNY 14,730.00 |
|
| RC207612L4 | Lenti ORF clone of Human peroxisomal biogenesis factor 1 (PEX1), mGFP tagged |
CNY 14,730.00 |
|
| RG207612 | PEX1 (tGFP-tagged) - Human peroxisomal biogenesis factor 1 (PEX1) |
CNY 14,160.00 |
|
| SC119848 | PEX1 (untagged)-Human peroxisomal biogenesis factor 1 (PEX1) |
CNY 8,944.00 |

{kind=link}